
What Exactly Is Web Crawling In SEO
Web crawling is the process where search engine crawlers—also known as spiders or bots—scan the [internet] to index and understand the content on various websites. This is a foundational element of search engine optimization (SEO) because crawlers gather data that search engines use to rank your website in search results. In layman’s terms, if your site is not crawlable, it’s like having a billboard in a desert; very few will ever see it.
Understanding web crawling is crucial for anyone who owns or operates a website. The more efficiently a search engine crawler can scan your site, the better your chances are for a favorable search engine ranking. That’s why it’s essential to build your website with crawlability in mind and to continually optimize its structure and content.
If you neglect this aspect of SEO, you risk having your site ignored by search engines, which can significantly impact your online visibility. In a digital age where the internet is often the first place people go to search for products, services, or information, being crawlable is not just an option; it’s a necessity.
Therefore, web crawling plays an indispensable role in connecting your site to your target audience. It is a topic you can’t afford to overlook when striving to improve your website’s SEO performance.
How Does Web Crawling Really Work
Understanding the crawling process requires a grasp of certain key terms and concepts. Let’s begin by discussing crawl budget, a critical factor in how search engines prioritize your site. The crawl budget is determined by two elements: crawl rate limit and crawl demand.
The crawl rate limit refers to the number of simultaneous connections a search engine bot can make to a site without overloading the server. On the other hand, crawl demand is tied to the popularity and updates of a website. The more frequently your content is updated, the higher the crawl demand becomes. These two factors together make up your site’s crawl budget, and managing it effectively is crucial for optimal performance in search engine rankings.
Search engines like Google have a limited crawl budget for each host, so you’ll want to make sure that your important pages are being crawled and indexed. If your crawl budget is wasted on irrelevant or low-quality pages, key pages may not be indexed, which would hinder your site’s SEO performance. Hence, understanding and optimizing for crawl budget is a vital part of website management.
Improving Your Website’s Crawl Efficiency
You’ve likely heard the phrase “content is king,” and indeed, high-quality content is pivotal for creating a superb user experience and enhancing SEO performance. Well-crafted content draws organic traffic to your site, engaging visitors and encouraging them to explore further. However, having great content alone is not sufficient. If you’re aiming for high visibility in search results, you must also ensure that your website is easily crawlable by search engine bots.
While top-notch content can improve your site’s SEO and drive organic traffic, it’s essentially ineffective if search engine bots can’t find or understand it. To bridge this gap, it’s crucial to pay attention to the technical aspects that make your site more crawlable. These details significantly impact your website’s SEO performance and your overall online visibility.
As we delve deeper into this subject, we’ll share a list of specific techniques geared toward crawl budget optimization and enhancing your crawl stats. In doing so, you’ll gain an understanding of how to strike a balance between user-focused content and technical SEO strategies, ensuring that your website is not only user-friendly but also bot-friendly.
Keep Your XML Sitemap Updated
One of the most straightforward yet often overlooked aspects of making your website more crawlable is maintaining up-to-date XML sitemaps. An XML sitemap serves as a roadmap for search engine bots, helping them find the most important pages on your site more quickly. By keeping your XML sitemaps current, you streamline the crawling process, making it easier for bots to access a comprehensive list of URLs and understand the structure of your site.
A well-maintained XML sitemap should always be in sync with the latest version of your robots.txt file. This ensures that search engine bots are provided with a consistent set of guidelines about which parts of your website should be crawled and which should be left out. This alignment is crucial for effective indexing and, subsequently, better SEO performance.
When it comes to listing URLs in sitemaps, it’s a best practice to include those that are canonical or, in other words, canonical links. Including canonical links ensures that you’re directing bots to the most authoritative versions of your pages, eliminating the risk of duplicate content issues. This is particularly beneficial for larger websites with multiple internal links leading to similar content.
Make Sure Your Server Response and Load Times are Fast and Healthy
When it comes to website optimization, the performance of your server is a critical factor that’s often overlooked. A highly performant server is like a well-oiled machine; you might not notice it when it’s functioning seamlessly, but you’ll definitely feel its absence when things go wrong.
Your server needs to be robust enough to handle the amount of crawling that search engine bots like Googlebot are programmed to do. In other words, it must be equipped to manage a high volume of crawl requests without any detrimental impact on server response time or generating errors.
Monitoring the host status of your website is essential, and tools like Google Search Console can be incredibly helpful for this. Your host status should always be in the green zone, indicating that your site is accessible and running smoothly. High server performance not only ensures that Googlebot can crawl your site effectively but also contributes to an improved user experience.
A critical metric to watch for is server response time, which should consistently trend below 300 milliseconds. Any server responses that go above this threshold could slow down the crawling process and negatively affect your SEO performance. Additionally, it’s crucial to monitor for 5xx status codes; these should make up less than 1% of server responses to maintain a healthy website.
Remove Content That No Longer Has Any Value
As your website grows, it’s easy to accumulate content that becomes outdated, irrelevant, or duplicated over time. Having a significant amount of such low-quality content can be detrimental for a couple of reasons. First, it diverts search engine crawlers from focusing on your new or recently updated content. Second, it contributes to index bloat, meaning your site’s index becomes filled with pages that don’t add value, affecting your overall SEO performance.
One of the quickest ways to identify and remove such content is by checking your Google Search Console. Specifically, look at the page report and filter by the exclusion ‘Crawled – currently not indexed.’ This will show you pages that Google has crawled but chosen not to index, which is often a sign of low-quality or irrelevant content. Pay special attention to folder patterns or other signals that indicate larger issues within your website’s architecture.
Once you’ve identified these problematic areas, you have a couple of options for addressing them. You can either merge similar content using a 301 redirect, which points users and search engine crawlers to the updated version of the page, or you can delete the unnecessary pages and serve a 404 status code. The latter is particularly useful for broken links or content that is so outdated it no longer serves any purpose.
Optimize Your Internal Linking Structure
One of the foundational elements that impact the crawlability of your website is your internal linking structure. Crawling primarily occurs through links, so it’s essential to get them right. Broken links or dead links can act as roadblocks, preventing search engine crawlers from indexing your content effectively. While external links can be powerful for building your site’s authority, they are often challenging to accumulate in large quantities without sacrificing quality. Internal links, by contrast, offer a scalable and impactful solution.

They are much easier to control and implement across your website and have a considerable positive impact on crawl efficacy. A good internal link structure can significantly improve the ease with which crawlers navigate your site, thus enhancing your site’s SEO performance.
In optimizing your internal linking, pay particular attention to elements that are often overlooked but crucial for mobile users. These include sitewide navigation, breadcrumbs, quick filters, and related content links. Make sure these features are not dependent on JavaScript, as that can negatively impact crawl efficacy and user experience, leading us to the topic of our next recommendation.
Prioritize The Use of HTML
While it’s true that Google’s crawlers have become increasingly adept at crawling JavaScript, Flash, and XML, it’s crucial to remember that Google isn’t the only search engine out there. Other search engines are still catching up in their ability to crawl and index more complex types of code effectively. Therefore, sticking to HTML in your source code is generally a safer bet for ensuring that your site is easily crawlable by all search engine bots.
HTML remains the gold standard when it comes to web development for SEO purposes. It is universally understood by all search engine crawlers, thereby increasing the odds that your site’s content will be indexed and ranked favorably across multiple platforms. Using HTML as the backbone of your site doesn’t mean you can’t use other technologies like JavaScript, but these should be considered supplementary rather than foundational.
Instruct Googlebot What (And Not) To Crawl (And When)
While it’s beneficial to use rel=canonical links and noindex tags to maintain a clean Google index for your site, these strategies do come at the expense of crawling. Every time Googlebot hits a page with these directives, it consumes some of your crawl budget even if the page isn’t ultimately indexed. So, you need to weigh the pros and cons: Is it worth allowing these pages to be crawled at all? If the answer is no, you can stop Googlebot right at the crawling stage by using a robots.txt file with a “Disallow” directive.
One key area to scrutinize is your Google Search Console’s coverage report. This invaluable tool allows you to identify pages that are excluded due to canonicals or noindex tags. Analyzing this data can help you determine if it’s more effective to block certain pages from being crawled rather than using indexing instructions, thereby conserving your crawl budget.
An optimized XML sitemap serves as a roadmap for Googlebot, directing it toward the most important, SEO-relevant URLs on your site. When we say “optimized,” we mean that the sitemap should be dynamically updated with minimal delay. It should also include metadata like the last modification date and time. This information signals to search engines when a page has undergone significant changes and needs to be recrawled, helping you better manage your crawl budget. By fine-tuning these elements, you effectively guide Googlebot and other search engine crawlers to the content that matters most, maximizing your site’s SEO performance.
Keep an Eye on Long, Convoluted Redirect Chains
Redirects are sometimes inevitable, especially on larger websites where structural changes and content updates are frequent. However, 301 and 302 redirects can have a domino effect on your crawl limit. This is particularly true when they’re chained together, forming long, convoluted redirect paths. These paths consume your crawl budget at a rate that can have search engine spiders abandoning the crawl before even reaching the most important pages you want to be indexed.
A single redirect chain might not seem like a big deal, but the issue amplifies with scale. For larger websites, the impact can be significant, affecting not just one but multiple pages, and potentially leading to lower indexation levels. Even if the impact isn’t immediate or blatantly obvious, the cumulative effect over time can degrade your site’s overall crawl efficiency.
Monitoring and optimizing your redirect paths is crucial. It’s not just about avoiding a negative impact today but about ensuring consistent, long-term crawlability for your site. So, keep a close eye on your redirects, untangle the chains where possible, and focus on creating a clean, streamlined path for search engine spiders to crawl and index your most valuable pages.
Google Search Console as a Basic Tool
Google’s Search Console is an essential utility for any website owner looking to optimize their site’s search performance. One of its key features is the ability to manually submit URLs for Googlebot to crawl. In most cases, the indexing status of the submitted URLs changes within an hour. This rapid indexing makes it an incredibly useful tool, especially when you have critical content that you want to appear in search results as quickly as possible.
However, Google Search Console does come with limitations. The most glaring one is the quota limit, which allows you to submit only 10 URLs within a 24-hour period. Given this constraint, manually submitting URLs is not a scalable tactic for larger websites with frequent updates. But this limitation shouldn’t deter you from leveraging the tool to your advantage.
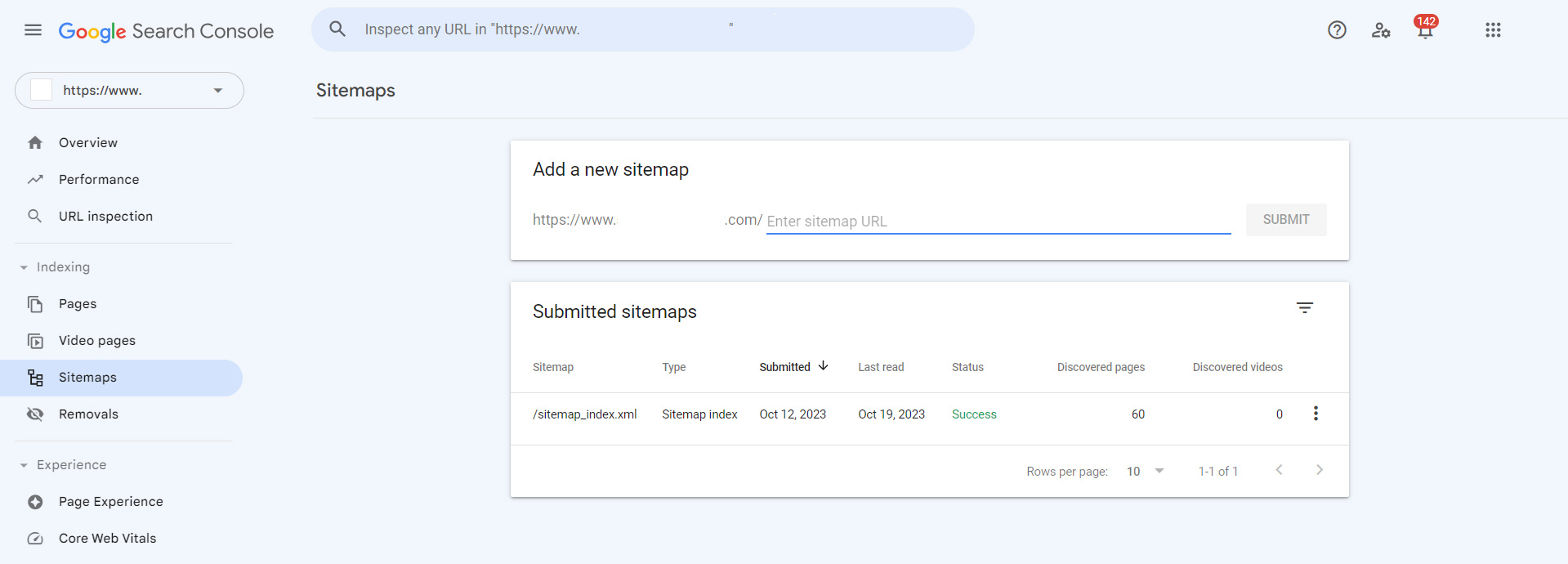
You can automate the submission process for high-priority URLs by using scripts that mimic user actions. This approach allows you to bypass some of the manual labor, making it easier to get your most important pages crawled and indexed quickly. In addition to individual URL submissions, Google Search Console also allows you to directly submit your sitemap. This feature simplifies the process of guiding Googlebot to crawl the most relevant sections of your site, providing another layer of control over your website’s search performance.
Working With an SEO Specialist
Navigating the complexities of SEO, especially within the medical field, can be a daunting task. Your primary focus should be on providing excellent patient care, not wrestling with Google algorithms and crawl budgets. A specialized SEO expert in medical marketing can handle this intricate work for you, ensuring your website performs at its best in search rankings while you continue to excel in your practice.
That’s where we come in. At Surgeon’s Advisor, we have over 20 years of industry experience, catering to healthcare professionals across all specialties, including a strong focus on plastic surgeons. We understand the unique SEO requirements of medical practices and have a long history of satisfied clients who can attest to our effectiveness. Why waste another minute struggling with SEO when you could be changing lives? Give us a call or visit our contact page today to get started on optimizing your online presence.